Enterprise AI Orchestration: The Missing Infrastructure Layer Keeping Your AI Pilots Stuck
Swapnil Somal · March 2026 · 8 min read
Infrastructure
Enterprise AI
Agentic Systems
Engineering teams at SF, NYC, and Bangalore companies spend 60-70% of AI project time on infrastructure — not AI. Here's the missing layer between "works in demo" and "runs at enterprise scale.
There's a pattern playing out in engineering teams from San Francisco's SoMa district to New York's Midtown, Austin's Silicon Hills, and Bangalore's Whitefield tech corridor.
60–70% of AI project time is spent not on the AI itself — but on the infrastructure around it.
Orchestration logic. Multi-environment deployments. Version control for prompts and agent logic. Cost attribution across model providers. Team access controls. Audit trails for compliance.
None of this is the interesting part of building AI. But all of it is what separates a compelling demo from a production system that runs reliably at enterprise scale.
This post is about that gap — what causes it, what it costs, and what purpose-built infrastructure looks like in 2026.
The State of Enterprise AI in 2026
Two years into the "agents era," the enterprise AI landscape has split in a way few predicted.
On one side: a handful of companies that moved fast with the right infrastructure, deployed AI agents into production workflows, and are now compounding their advantages. Customer support resolution times down 60%. Operations costs cut in half. Entire workflow categories running on agents instead of humans.
On the other side: a much larger group — well-funded, technically sophisticated — whose AI initiatives are still living in pilot status. Not because the technology doesn't work. Because the infrastructure around it doesn't exist.
San Francisco's enterprise SaaS companies are especially exposed. They're selling AI features to enterprise customers while struggling to build reliable AI infrastructure internally. Their engineering teams notice the irony.
Why Enterprise AI Pilots Don't Make It to Production
The failure mode is consistent enough to name explicitly. An engineering team evaluates an LLM, builds a proof of concept that works in testing, gets stakeholder buy-in. Then the project stalls.
Here's why:
The Coordination Problem
A real enterprise AI system involves multiple agents handling different parts of a workflow. Who owns the prompt for the classification agent? Who manages the Salesforce integration? When the customer support agent gives a wrong answer in production — which part of the system broke?
Without proper tooling, these questions take days to answer.
The Environment Problem
Consumer AI tools have one environment. If you test a prompt change and it breaks something, you find out in production, in front of customers. Enterprise software has never worked this way — and enterprise AI shouldn't either.
The Cost Problem
Token costs across GPT-4o, Claude, and open-source models are non-trivial at scale. Most companies discover this when the first invoice arrives. Proper AI infrastructure surfaces cost data at the agent, workflow, and model level — before you ship.
The Versioning Problem
When an agent prompt needs to change, what's the rollback path? Which version was running last Tuesday when the incident happened? Python code has git. Agent logic needs equivalent version control.
The Collaboration Problem
AI agent systems built by one engineer are fragile. When that engineer leaves — or the team scales from one to five — the system breaks without proper access controls, documentation, and collaborative tooling.
None of these problems get solved by choosing a better LLM. They require infrastructure.
What It Actually Costs to Build Enterprise AI Infrastructure Yourself
The companies that have cracked enterprise AI in production largely built their own infrastructure. Here's what that includes:
A custom orchestration layer routing requests between specialized agents
An internal prompt management system with versioning
A logging and observability stack tracing decisions at the agent level
A testing framework for evaluating outputs before promoting to production
An integration layer connecting agents to CRMs, internal tools, and data systems
For a mid-size SaaS company in San Francisco, building this from scratch is a 6–12 month engineering project requiring 3–5 senior engineers. At $200–250K fully loaded cost per engineer per year, that's $300K–$1.5M in pure infrastructure investment — before a single business outcome is delivered.
Most companies can't afford this. And even those that can are questioning whether it's the right use of engineering resources.
The AI Operating System — A New Infrastructure Category
A new platform category is taking shape that addresses this directly: the AI Operating System — a layer that sits between cloud AI providers (GPT-4o, Claude, Gemini) and production enterprise applications.
The AI OS provides:
Visual agent design — build multi-agent workflows without writing orchestration code from scratch
Multi-environment deployment — the same dev/staging/production model enterprise software has always used
Version control for agent logic — rollbacks, audit trails, change history
Cost observability — token usage broken down by model, agent, environment, and time
Collaboration tooling — multiple engineers working safely on shared agent systems
Native integrations — Salesforce, Jira, Slack, WhatsApp, custom APIs out of the box
The analogy that resonates most with CTOs: this is what Kubernetes did for containerized workloads, or Terraform for cloud infrastructure. It didn't replace the underlying technology — it made deploying and managing it at enterprise scale feasible.
Enterprise AI Use Cases by Market
San Francisco — SaaS Customer Success Automation
SF's SaaS companies have a specific problem: customer success is expensive and churn prevention is existential. AI agents are handling tier-1 and tier-2 success workflows — onboarding nudges, health score monitoring, renewal reminders, escalation routing.
The architecture that works: a Master Agent monitors customer health signals and delegates to specialized sub-agents for different scenarios. An at-risk account gets a different workflow than a dormant one.
New York — Financial Services Compliance
Wall Street's financial firms have requirements that make off-the-shelf tools non-starters: Human-in-the-Loop approvals, PII redaction, encrypted APIs, full audit trails, and explainability for every AI decision.
Agentic AI in financial services isn't about removing humans from the loop. It's about ensuring humans are only in the loop when they need to be. Routine classification and initial compliance checks run autonomously. High-value decisions pause for human review, then resume with full context.
Austin — Shipping AI Products Fast
Austin's startup scene has different constraints. The mandate is speed. A founder describing a workflow — "read incoming emails, classify the issue, pull CRM data, draft a response, queue for review" — and having the platform generate the agent graph and tool code is the difference between a 2-week build and a 3-month build.
India — BPOs and Banks at Volume
India's BPOs and banks are dealing with 2M+ interactions per month. At that volume, a 60% faster resolution rate is immediate, measurable ROI. One week of Indian enterprise data generates more training signal than a US equivalent does in a quarter.
The challenge: a WhatsApp bot and an email agent are two separate projects. They should be one workflow.
The Technical Architecture Behind Production-Grade Agentic AI
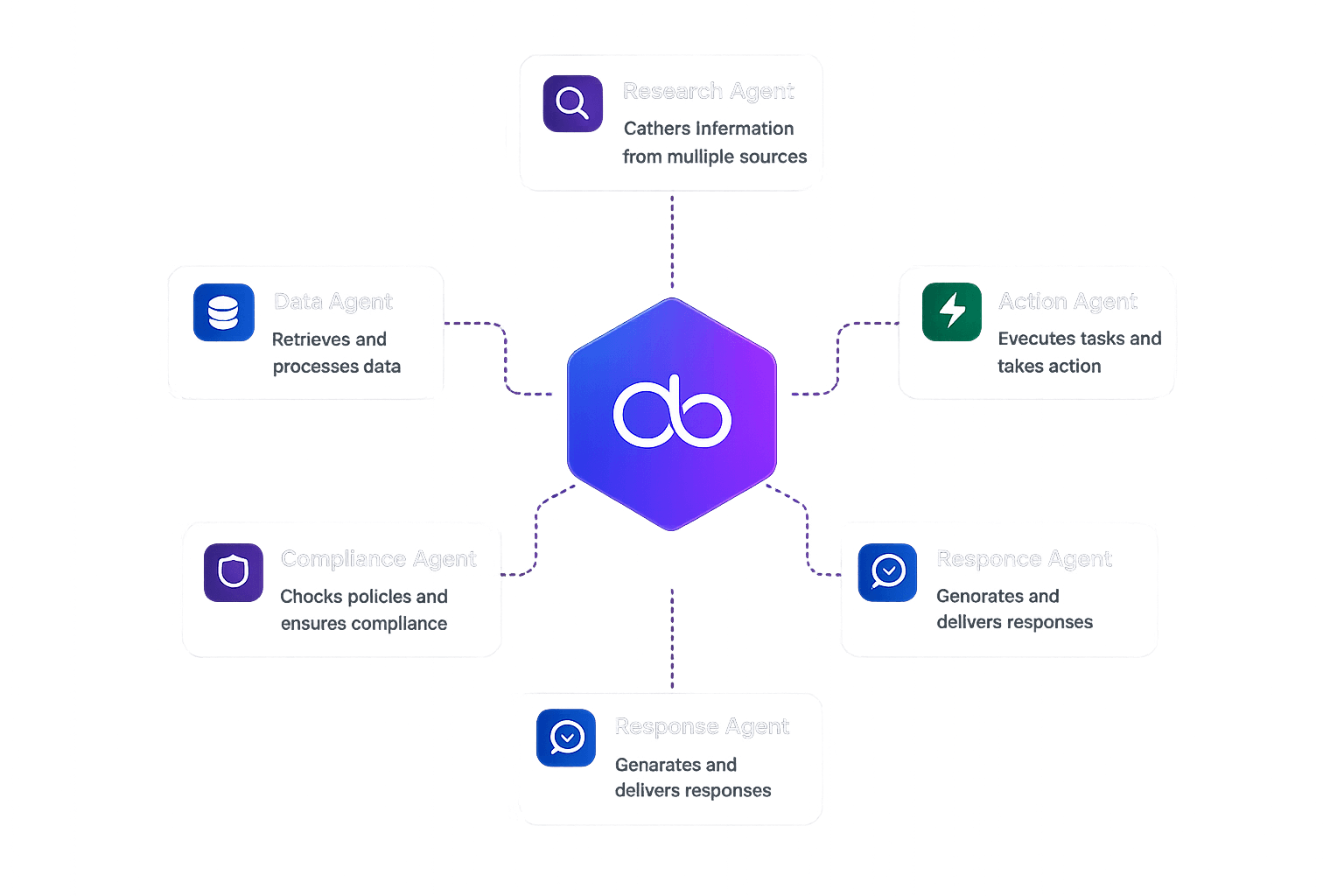
Master/Child Agent Pattern
The most reliable architecture for complex enterprise workflows is hierarchical. A Master Agent handles intent classification and routing. Specialized Child Agents handle specific domains. The Master doesn't use hardcoded routing — it uses LLM reasoning to decide which agent to invoke, handling edge cases the original designer never anticipated.
Agent-to-Agent (A2A) Communication
In multi-step workflows, agents need to pass context between each other. Proper A2A means variables captured by one agent are available to downstream agents in the same session — no duplicate data fetching, no context loss.
RAG Integration
For knowledge-intensive workflows, agents query organizational knowledge bases and retrieve relevant passages with citation, not hallucination.
Buyer's Framework: Evaluating Enterprise AI Orchestration Platforms
For CTOs and engineering leaders evaluating this category:
Build vs. Buy: How many engineering months to build equivalent infrastructure internally? At current SF or NYC engineering costs, what's the 24-month total cost comparison?
Scalability: Can the platform handle 10x your current peak load? What's the latency profile at volume?
Enterprise Security: SOC 2 compliance, SSO integration, RBAC, audit logging — non-negotiable for enterprise.
Extensibility: Can you bring your own models? Write custom tools in Python? Integrate with internal systems via standard APIs?
Observability Depth: Can you trace exactly what happened in a specific interaction, down to which node produced which output?
Frequently Asked Questions
What is enterprise AI orchestration?
Enterprise AI orchestration is the infrastructure layer that manages how multiple AI agents work together in production — handling routing, versioning, deployment environments, observability, and integration with business systems.
Why do enterprise AI pilots fail to reach production?
The most common causes are the coordination problem (no tooling to manage multi-agent systems), the environment problem (no dev/staging/production separation), cost unpredictability, lack of version control for agent logic, and no collaboration tooling for engineering teams.
What's the difference between an AI chatbot and a multi-agent AI system?
A chatbot handles a single conversational thread with one model. A multi-agent system coordinates multiple specialized AI agents — each owning a specific task — that hand off work between each other, escalate to humans when needed, and operate across multiple channels and workflows simultaneously.
What does "AI OS" mean?
AI Operating System — a platform layer that sits between cloud AI infrastructure (GPT-4o, Claude, Gemini) and production enterprise applications. It handles deployment, orchestration, observability, versioning, and governance for multi-agent AI systems at enterprise scale.
How long does it take to deploy a multi-agent AI system with Phinite?
Most teams go from first workflow to production in days, not months — compared to the 6–12 month custom build that most enterprises attempt first.
The Compounding Advantage
Companies that get AI infrastructure right in 2026 aren't just saving engineering time today.
Every agent deployed generates performance data. That data feeds improvements. Improved agents get redeployed. New use cases build on the same infrastructure.
This is fundamentally different from traditional software — where a deployed feature is static until someone rewrites it. AI agent systems that are properly instrumented improve over time, continuously, without proportional engineering investment.
The question for enterprise technology leaders isn't whether to build this advantage. It's whether to build the infrastructure yourself — or use a platform built for exactly this purpose.
Phinite is an AI Operating System for multi-agent systems.
Other Blogs

Phinite vs LangGraph: Which One Fits Your Multi-Agent AI Project?
LangGraph has become one of the most widely used tools for building multi-agent AI systems. It's open-source, well-documented, and backed by the LangChain ecosystem. If you've prototyped an agent workflow, there's a decent chance you used LangGraph to do it.
What Is a Multi-Agent AI Platform? A Complete Guide for 2026
If you've been following enterprise AI over the past year, you've probably noticed a shift in the conversation. The focus has moved from single chatbots and standalone models to something more ambitious: systems where multiple AI agents collaborate, delegate, and get real work done.
Enterprise AI Orchestration: The Missing Infrastructure Layer Keeping Your AI Pilots Stuck
Engineering teams at SF, NYC, and Bangalore companies spend 60-70% of AI project time on infrastructure — not AI. Here's the missing layer between "works in demo" and "runs at enterprise scale.